
React practical SEO


Photo by https://unsplash.com/photos/qIu77BsFdds
All the React and Front-end essentials for SEO in 8 minutes
Let’s be honest, as Front-end engineers, SEO is not a preferred subject.
Most of the time, doing some research on the subject end-up reading a lot of articles on non-technical “SEO magic sauce”.
This article will introduce you to the technical best practices, but also a convenient checklist, to ensure that your content is readable, discoverable, and ready to be shared on socials.
Helping search engines
Let’s start with some basics to help search engines (Googlebot, etc.) to crawl your website or public SPA.
Make your site easier to crawl.
Two main things make it difficult for search bots: XHR and content discovery (for big websites).
Google bot - for example - is fully capable of indexing pages using JavaScript; however, the fear of having a slow DOM rendering that will end up in a “blank indexing” is maybe a risk you don’t want to take.
For this reason, most people prefer to avoid having JavaScript-based rendering for search engines.
The current React/Node.js ecosystem provides multiple solutions to this problem:
- Server-side Rendering (SSR)
- Static Site Generation (SSG)
For both approaches, the goal is to deliver HTML to the browser first-render.
Let’s dig a bit into the two approaches:
SSR
Server-side Rendering
This solution consists of having the server rendering the full HTML content as each request.
Then, once the page is loaded, the JavaScript - SPA - will handle the non-SEO vital interactions and logic.
SRR is an excellent approach for SEO on user-defined or “dynamic content” pages
Many tools allow implementing SRR:
- Next.js
- ReactDOMServer
SSG
Static Site Generation
A more “radical” approach consists of making your website fully statistically generated, meaning that your pages will be transformed to HTML at build time (during your CI or deployment phase).
SSG is an excellent approach for SEO for static content like blog or landing pages
Many tools allow implementing SSG:
- Next.js (ISR & SSG)
- Gatsby
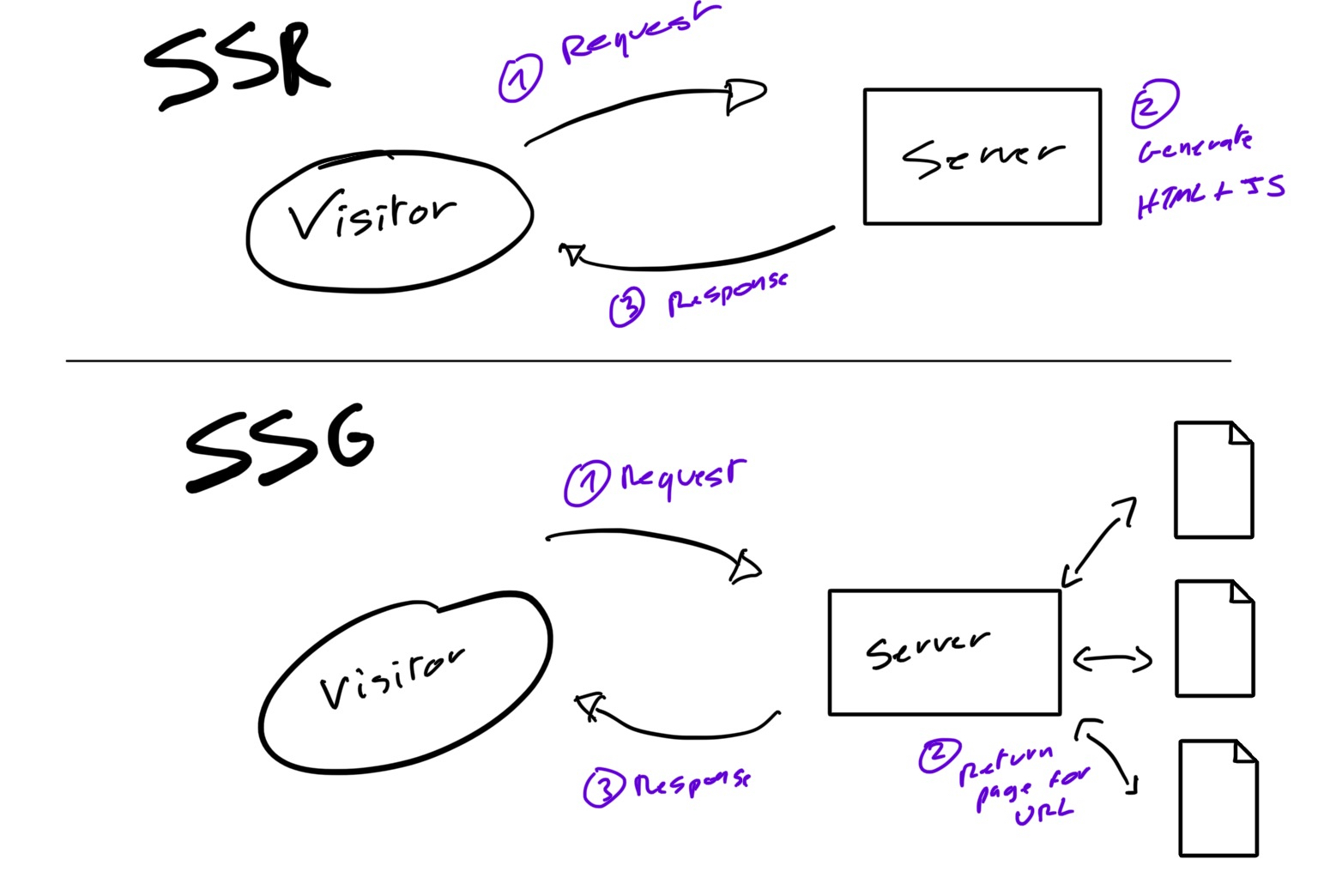
SSR generate the HTML + React server side at each request, while SSG does it at build time (faster for visitor)
Using SSR or SSG will also provide better performance to your users, which is also a significant criterion for search engines like Google that will soon include the “first paint” and “time to interactive” in your SEO score (especially on mobile).
For more information on this subject, please refer to this great article:
Get Insights on your website performance
Once your website optimized for SEO performance, you can leverage the Google Insights tool to audit it:
You will get a realtime report with some tips:
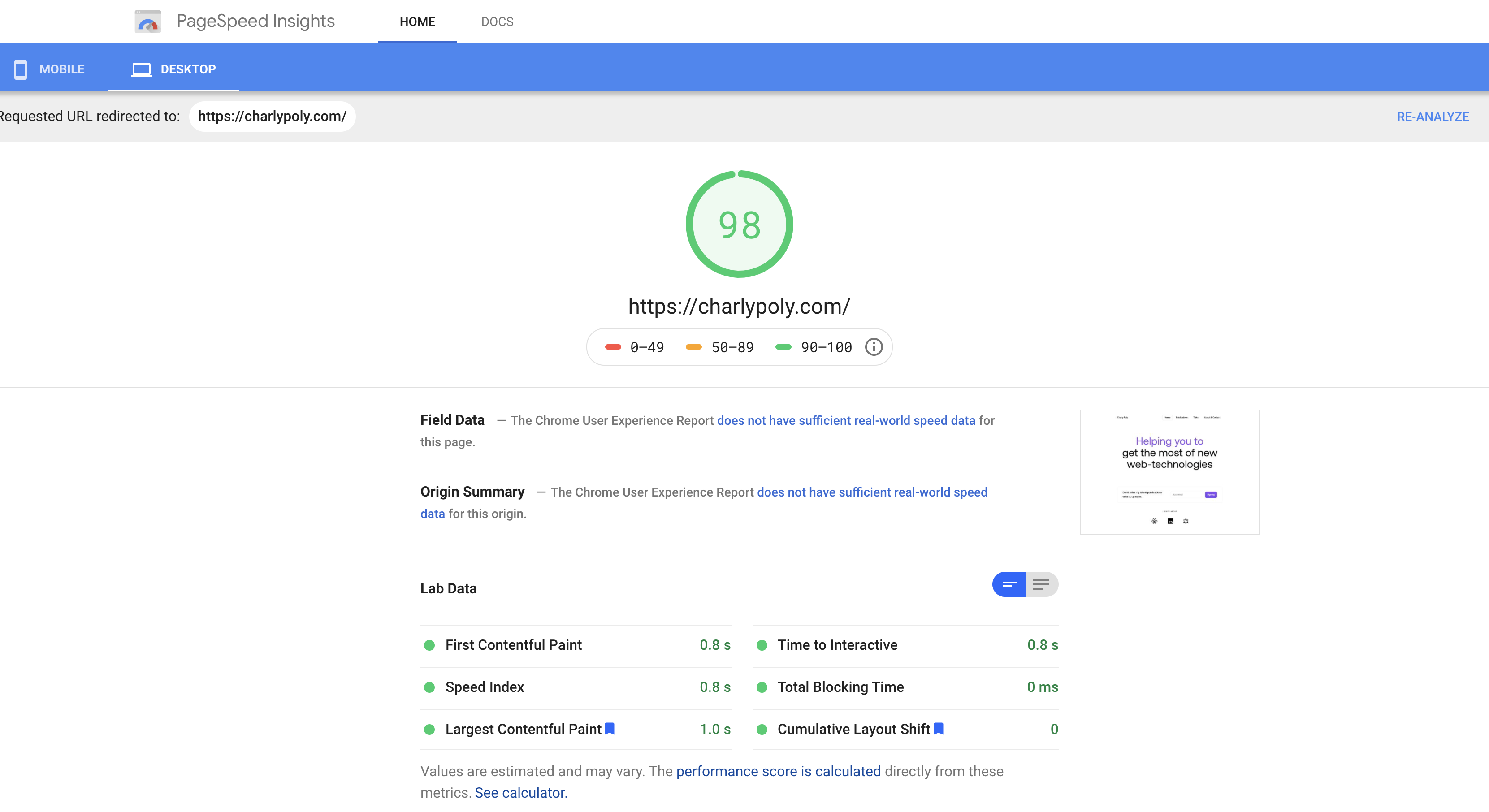
Help the search bots finding content.
Once your content is guaranteed to be accessible by search crawlers, you need to make it discoverable and indicate which content should be ignored.
Prevent search engines from index content
Let’s start by preventing search engines from indexing specific content.
It can be the case, for example, of feature-envs (called Previews Env on Vercel or Review Apps on Heroku) or private pages.
Some hosting services, like Vercel, already got you covered by preventing search engines from index content from preview environments.
If you have a custom feature-envs system or pages you don’t want search engines to index that you host yourself or somewhere else than Vercel, you will have to implement the following:
If you host your pages or feature-envs on a provider (Heroku, Github pages, etc.)
For this configuration, I would suggest to take the HTML approach by using the dedicated <meta> tag as it follows:
1
2<html>
3<!--- … --->
4 <head>
5 <meta name="robots" content="noindex" />
6 <!--- … --->
7 </head>
8<!--- … --->
9</html>
10
If you host yourself your pages or feature-envs
A less invasive approach consists of updating the server serving your website/SPA to send a custom response header that will be read by search bots.
To prevent a specific environment (example: `NODE_ENV !== ‘production’) from being indexed by search engines, please ensure to add the following response header:
1X-Robots-Tag: noindex
(This is what Vercel is doing for preview environments)
Now that we saw how to prevent search bots from unwanted index content, let’s now see how we can make sure that they index all your available content for indexing.
Ensure that all your pages can be discovered
Most search bots end-ups indexing all the content of your website/public SPA by navigating the index page’s links.
However, it is possible to provide a specific file that indicates to search bots how to access all the indexable content of your site; this file is called a “site-map.”
Beyond just listing all the “indexable” pages of your website, site-maps also indicate to search bots how often each of them is updated.
Let’s see an example with the site-map of charlypoly.com:
1<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:news="http://www.google.com/schemas/sitemap-news/0.9" xmlns:xhtml="http://www.w3.org/1999/xhtml" xmlns:mobile="http://www.google.com/schemas/sitemap-mobile/1.0" xmlns:image="http://www.google.com/schemas/sitemap-image/1.1" xmlns:video="http://www.google.com/schemas/sitemap-video/1.1">
2 <url>
3 <loc>https://charlypoly.com/</loc>
4 <changefreq>daily</changefreq>
5 <priority>0.7</priority>
6 <lastmod>2020-11-27T15:36:15.987Z</lastmod>
7 </url>
8 <url>
9 <loc>https://charlypoly.com/hire-me</loc>
10 <changefreq>daily</changefreq>
11 <priority>0.7</priority>
12 <lastmod>2020-11-27T15:36:15.987Z</lastmod>
13 </url>
14 <url>
15 <loc>https://charlypoly.com/publications</loc>
16 <changefreq>daily</changefreq>
17 <priority>0.7</priority>
18 <lastmod>2020-11-27T15:36:15.987Z</lastmod>
19 </url>
20 <url>
21 <loc>https://charlypoly.com/talks</loc>
22 <changefreq>daily</changefreq>
23 <priority>0.7</priority>
24 <lastmod>2020-11-27T15:36:15.987Z</lastmod>
25 </url>
26 <url> <loc>https://charlypoly.com/publications/3-annotations-to-use-in-your-graphql-schema</loc>
27 <changefreq>weekly</changefreq>
28 <priority>0.5</priority>
29 <lastmod>2020-11-27T15:36:15.987Z</lastmod>
30 </url>
31<!-- … -->
32</urlset>Sitemaps provide to search for bots all information regarding your website/SPA content.
The question that you may have is, “do I need a sitemap?”.
Let’s see some tips from the Google documentation:
You might need a sitemap if:
- Your site is really large. As a result, it’s more likely Google web crawlers might overlook crawling some of your new or recently updated pages. [...]
- Your site is new and has few external links to it. Googlebot and other web crawlers crawl the web by following links from one page to another. As a result, Google might not discover your pages if no other sites link to them. [...]
You might not need a sitemap if:
[...]
-** Your site is comprehensively linked internally.** This means that Google can find all the important pages on your site by following links starting from the homepage.
As a rule of thumb, use sitemaps if:
- your website has many pages or a complex structure
- your website is new
- your tech stack allows you to generate one quickly (see below)
This website, built with Next.js, uses next-sitemap as a build step to automatically generate the site map.
If you are building a SPA using react-router, you might want to take a look at react-router-sitemap.
Check your website sitemap
Once your website or application is ready at /sitemap.xml of your domain, you can go to the Google Search Console and provide the sitemap file URL to check.
You will then have a report on your sitemap validity:
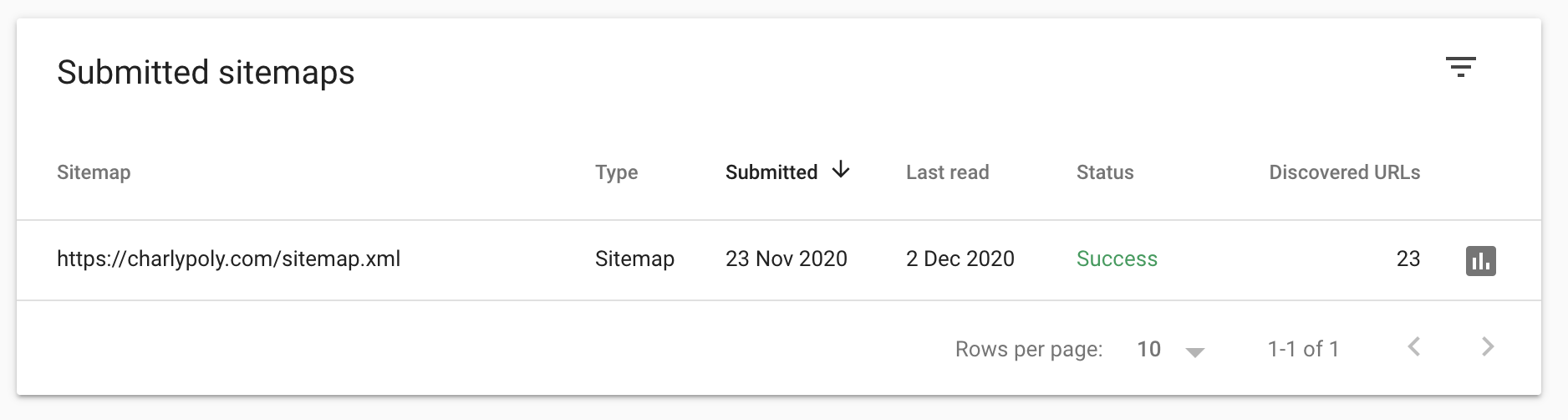
Describe your content
Having a performant and easy to navigate website/app is not sufficient for a good SEO.
We’re now going to focus on the content itself and make sure that search bots can extract meaningful information from your web-pages properly.
Help search bots get the essential information of a page.
Without providing the proper <meta> tags, search bots will index the first paragraphs of a page’s visible text as the main summary.
The following tags are essential for a good SEO and minimum viable search results appearance:
1<html>
2<!--- … --->
3 <head>
4 <title>From REST to GraphQL</title>
5 <meta name="description" content="All the tools to get your existing REST APIs working with GraphQL" />
6 <meta name="keywords" content="react, graphql,feedback" />
7 <meta name="author" content="Charly Poly" />
8 <!--- … --->
9 </head>
10<!--- … --->
11</html>
SEO tags for the “From REST to GraphQL” article
You most likely already knew this bit of information; however, I insist on the fact that providing the above SEO tags are the bare minimum for a good search results appearance.
Enhance search result appearance with JSON-LD schema
Nowadays, search engines like Google provide advanced results appearance by leveraging JSON-LD.
Using JSON-LD allows to provides information that does not fit in standard <meta> tags to have customized search results such as Breadcrumbs:
Providing advanced navigation/context information on a page
But also rich information such as Article metadata:
Providing article information such as date, main image, summary
This “structured data,” used by Search engines, relies on JSON-LD, allowing to provide extra information for many types of data such as Article, Book, Review, Event, Course, and more.
Let’s see a practical example of the JSON-LD “NewsArticle” document for the “From REST to GraphQL” article:
1{
2 // indicate that this JSON-LD document is using the schema vocabulary
3 "@context": "[http://schema.org](http://schema.org)",
4 // we are describing an object of “NewsArticle” type
5 "@type": "NewsArticle",
6 // the properties below are defined by the “NewsArticle” type
7 "image": [
8 "https://charlypoly.com//images/publications/from-rest-to-graphql-cover.jpeg"
9 ],
10 "url": "https://charlypoly.com/publications/from-rest-to-graphql",
11 "dateCreated": "2020-12-02T23:00:00.000Z",
12 "datePublished": "2020-12-02T23:00:00.000Z",
13 "dateModified": "2020-12-02T23:00:00.000Z",
14 "headline": "From REST to GraphQL",
15 "name": "From REST to GraphQL",
16 "description": "All the tools to get your existing REST APIs working with GraphQL",
17 "identifier": "from-rest-to-graphql",
18 "keywords": [
19 "graphql",
20 " react"
21 ],
22 "author": {
23 // this property is actually an object of type “Person”
24 "@type": "Person",
25 "name": "Charly Poly",
26 "url": "https://charlypoly.com/hire-me"
27 },
28 "creator": [
29 "Charly Poly"
30 ],
31 "mainEntityOfPage": "https://charlypoly.com/publications/from-rest-to-graphql"
32}
We provide rich information that does not fit in `<meta>` tags such as multiple images, author properties, headline, title, description distinction.
Using JSON-LD in your React application or website is simple!
The document must be passed in a element in your DOM as it follows:
1<script
2 type="application/ld+json"
3 dangerouslySetInnerHTML={{ __html: toJSONLD(yourDataToTransform) }}
4/>
If you’re interested in digging more into the subject, a good start is the Google guide to structured data:
For the more curious and bravest, the official schema.org documentation is a reference:
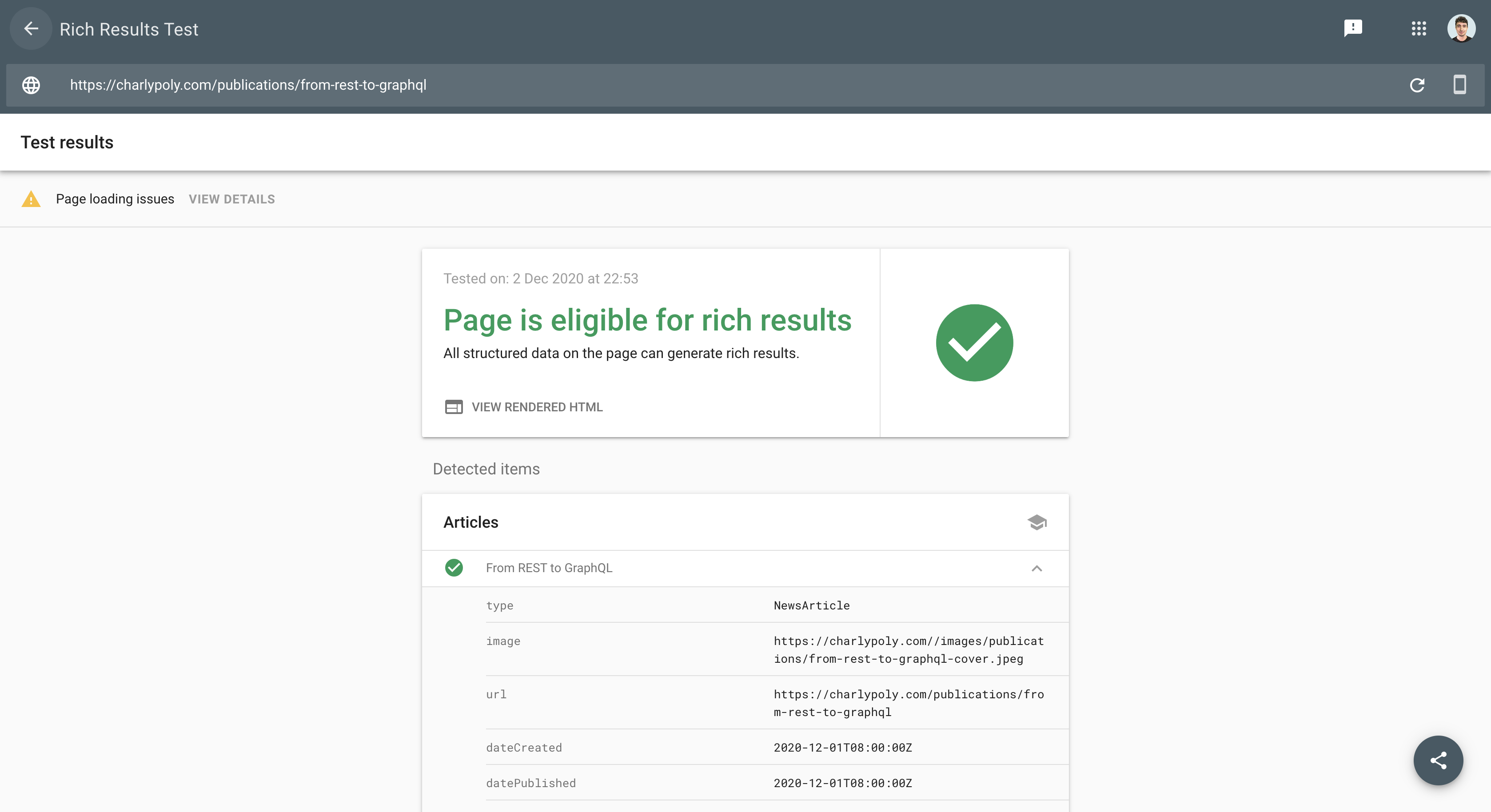
Ensure that your structured data is valid
Again, Google provides a tool for this, called “Rich Results Test”: https://search.google.com/test/rich-results
By providing a publicly accessible URL, you will get a report as it follows:
Social/Share previews
This subject is beyond classical SEO, but I consider it vital to cover the modern social web.
You always wondered how social website/applications and messaging applications get the preview of URLs?
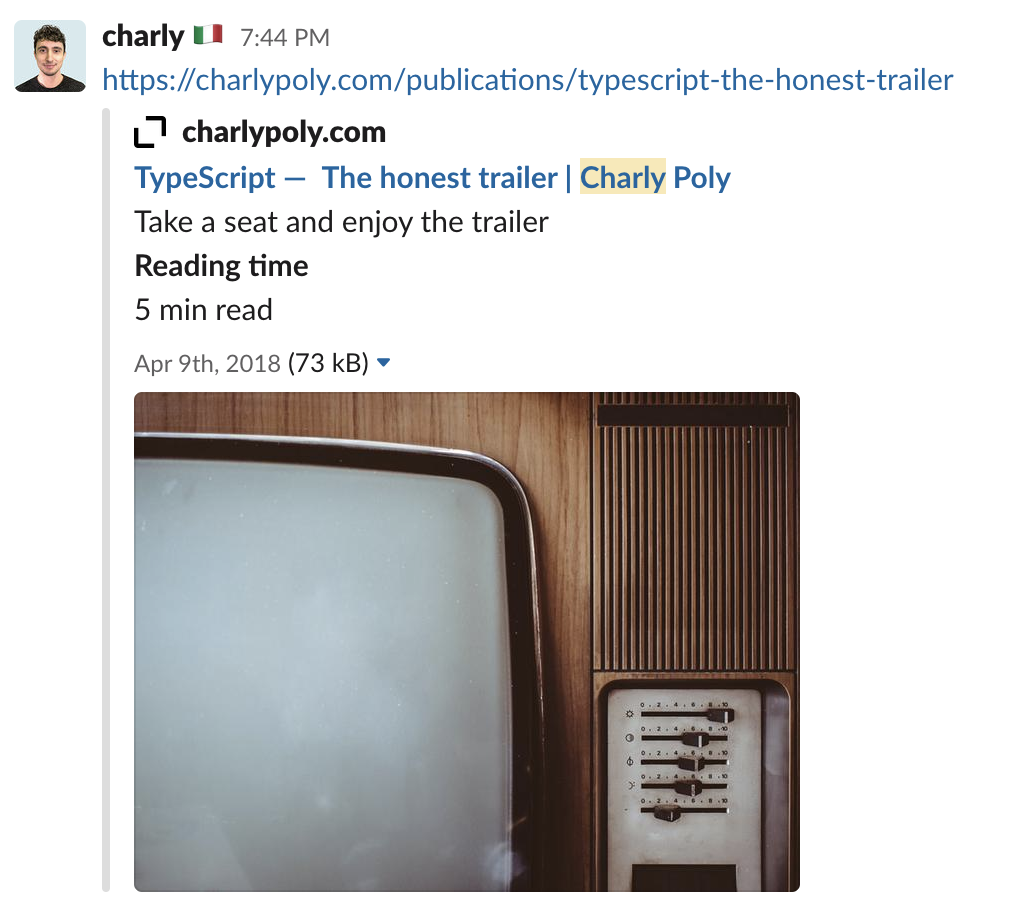
Slack preview of the “TypeScript - The honest trailer” article link
There is no magic! Applications and websites use crawlers and well-defined standards to get the image, title, description preview, and more.
Let’s see how to make your website/application compatible with rich/share preview.
Why Facebook, Twitter, and other services do not rely on JSON-LD?
JSON-LD is based on the Schema.org vocabulary which is a general-purpose vocabulary for structured data.
Schema.org is a very complete and complex project which is also led by Google, Microsoft, Yahoo, and Yandex.
While the conclusion could be political, the main reason is that Facebook and Twitter, by bringing respectively Open Graph and Twitter Card conventions, provided a simple solution to share article-like content, while Schema.org has a bigger goal (covering a lot of different structured data types).
Facebook Open Graph

“From REST to GraphQL” preview on Facebook
Facebook’s solution in getting metadata for sharing is Open Graph, which consists of a convention based on <meta> tags:
1<meta property="og:title" content="From REST to GraphQL | Charly Poly" />
2<meta property="og:type" content="article" />
3<meta property="og:image" content="https://charlypoly.com//images/publications/from-rest-to-graphql-cover.jpeg" />
4<meta property="og:description" content="All the tools to get your existing REST APIs working with GraphQL" />
5<meta property="og:url" content="https://charlypoly.com/publications/from-rest-to-graphql" />og:title, og:image, og:description, and og:url are generic property that Facebook expects to find when an URL is being shared, those are the basic metadata needed.
Similar to the previous JSON-LD example, an og:type can be provided to specify the type of content, here an article.
Providing an og:type property indicates to the Facebook bot that additional specific property for this type may be found as it follows:
1<meta property="article:published_time" content="2020-12-01T00:00:00.000Z" />
2<meta property="article:modified_time" content="2020-12-01T00:00:00.000Z" />
3<meta property="article:section" content="Software" />
4<meta property="article:tag" content="graphql" />
5<meta property="article:tag" content=" react" />
6<meta property="article:author:first_name" content="Charly" />
7<meta property="article:author:last_name" content="Poly" />
For more information, please refer to the official Facebook Open Graph documentation:
Twitter cards
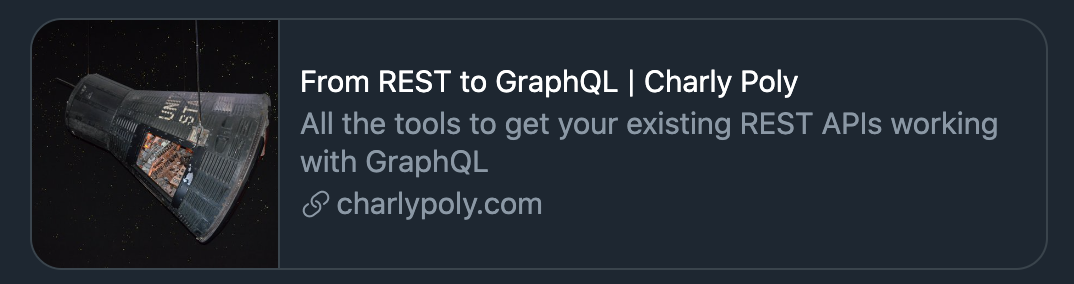
“From REST to GraphQL” preview on Twitter
Twitter is providing its own convention called Twitter cards:
1<meta name="twitter:card" content="summary" />
2<meta name="twitter:site" content="@where_is_charly" />
3<meta name="twitter:title" content="From REST to GraphQL | Charly Poly" />
4<meta name="twitter:description" content="All the tools to get your existing REST APIs working with GraphQL" />
5<meta name="twitter:image" content="https://charlypoly.com//images/publications/from-rest-to-graphql-cover.jpeg" />Very similar to Facebook Open Graph, you will notice some key difference:
- twitter:card is required for Twitter to enable crawling on the page
- twitter:site that specify the Twitter account linked to the page
For more information, please refer to the official Twitter Cards documentation:
How to check social previews?
You’re all set, your react website or application implements the required OpenGraph and Twitter tags, let’s now ensure that is working as expected!
Twitter provides a tool to quickly preview a URL: https://cards-dev.twitter.com/validator
So does Facebook: https://developers.facebook.com/tools/debug/
If you’re a productivity maniac, you can use the following Chrome extension that will provide previews for Twitter and Facebook in a few clicks: Open Graph Preview
We use cookies to collect statistics through Google Analytics.