
Issues I went through while building a GraphQL client


Photo by https://unsplash.com/photos/KxeFuXta4SE
cache, queries optimisation and “simultaneous requests in resolution”
There are only three hard things with GraphQL
This sentence is famous:
There are only two hard things in Computer Science: cache invalidation and naming things.
— Phil Karlton
— Phil Karlton
Here is the GraphQL version:
There are only three hard things with GraphQL resolvers: cache, queries optimisation and “simultaneous requests in resolution”
I recently built a Spotify Web API GraphQL client called spotify-graphql.
Here’s how I deal with theses 3 issues:
cache, queries optimisation and “simultaneous requests in resolution”.
cache, queries optimisation and “simultaneous requests in resolution”.
Caching
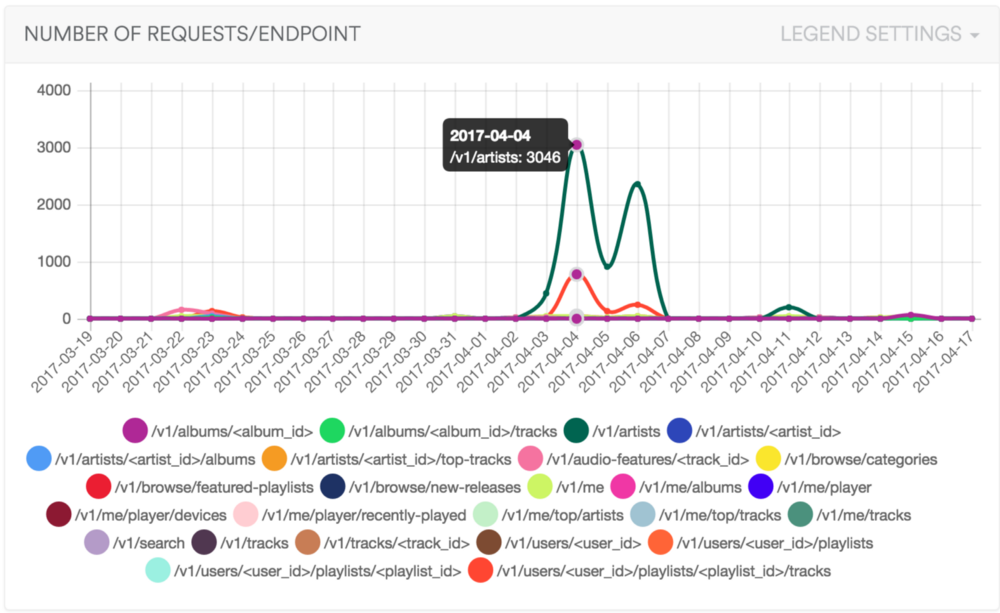
Example of “for all my playlist, give me all tracks with artists”
While testing my Spotify client, I noticed that I could optimise the number of HTTP calls.
In Spotify case, data “repeats a lot”, in a user playlists we often find same artists, tracks, etc…
In Spotify case, data “repeats a lot”, in a user playlists we often find same artists, tracks, etc…
So, let’s inspect this query:
1{
2 me {
3 playlists {
4 artists {
5 id
6 name
7 }
8 }
9 }
10}Running this query on my account will results to 50+ calls on /api/v1/artists/2YZyLoL8N0Wb9xBt1NhZWg since I have a lot of playlists with some good Kendrick Lamar.
So, I decided to use a LRU-cache — size = 50 — at the HTTP client level.
LRU stands for Least Recently Used, basically it means that, at write time, the cache will only keep the 50 mosts hit items.
It’s fit particularly for the “several same artist” case.
Using this cache system ensure a maximum “hits” with a minimum memory footprint.
LRU stands for Least Recently Used, basically it means that, at write time, the cache will only keep the 50 mosts hit items.
It’s fit particularly for the “several same artist” case.
Using this cache system ensure a maximum “hits” with a minimum memory footprint.
I believe that caching strategy is specific to each client, especially to each data provider you are accessing (REST API, SQL, files, etc…)
Here are some good ressources about this subject:
- http://graphql.org/learn/caching/
- https://philsturgeon.uk/api/2017/01/26/graphql-vs-rest-caching/
- https://github.com/graphql/dataloader
Simultaneous requests in resolution
1{ # get my followed artists tracks
2 me {
3 artists { # "n" simultaneous HTTP calls to fetch artist tracks
4 tracks {
5 track {
6 name
7 }
8 }
9 }
10 }
11}What I call “simultaneous requests in resolution” issue is maybe specific to spotify-graphql auto-pagination features.
Since tracks and artists queries will returns all items after a pagination loop, the resolution for each artists tracks will trigger a lot of simultaneous resolution — so, HTTP calls.
Since tracks and artists queries will returns all items after a pagination loop, the resolution for each artists tracks will trigger a lot of simultaneous resolution — so, HTTP calls.
To fix this, spotify-graphql uses a “polling lock” system that ensure that only one resolution is made at a given time — it’s namespace based.
Here’s an example of playlist.tracks resolver implementation:
1tracks(playlist, variables) {
2 return syncedPoll('Playlist.tracks', () => {
3 return
4 paginatorFromVariables('OffsetPaging', variables)
5 (spotifyApiClient,
6 'getPlaylistTracks',
7 response => response.body.items,
8 playlist.owner.id,
9 playlist.id).then( (tracks) => tracks });
10 }, variables.throttle || 5);
11}- syncedPoll return a Promise and ensure that the given callback will be executed when a “slot” is available.
- paginatorFromVariables is a factory return a “configured” function from given variables
The paginator uses Spotify API JSON response format to determine if pagination is finished.
I don’t know if many people had this issue while developing GraphQL, but I find it interesting to develop a respectful querying strategy — by avoiding massive calls on API.
Queries optimizations
A good example is the following query:
1{
2 me {
3 playlists {
4 tracks {
5 track {
6 artists(full: 1) {
7 popularity
8 }
9 }
10 }
11 }
12 }
13}Spotify API has a notion of FullObject and SimpifiedObject.
By default, tracks includes a simplified version of the linked album object with a limited subset of fields.
In order to get a “full object” of the resource, you have to call the dedicated endpoint: /api/v1/artist/:id .
One naive implementation would be to call this endpoint in the track.artists resolvers many times as needed.
By default, tracks includes a simplified version of the linked album object with a limited subset of fields.
In order to get a “full object” of the resource, you have to call the dedicated endpoint: /api/v1/artist/:id .
One naive implementation would be to call this endpoint in the track.artists resolvers many times as needed.
A smart approach is to use “bulk endpoints” provided by Spotify: /api/v1/artists?ids<id,id,...> — maximum of 50 ids.
So the resolvers should group HTTP calls by chunks of 50 ids.
So the resolvers should group HTTP calls by chunks of 50 ids.
1artists(track: any, variables: any) {
2 if (!!variables.full) {
3 return syncedPoll('Track.artists', () => {
4 return new Promise((resolve, reject) => {
5 let queries: any = \_(track.artists).
6 map('id').
7 compact().
8 chunk(50).map((idsToQuery: any\[\]) => {
9 return (): Promise<any> => {
10
11 return safeApiCall(
12 spotifyApiClient,
13 'getArtists',
14 (response)=>
15 response.body.artists,
16 idsToQuery
17 );
18 };
19 }); // end of \_.map()
20 sequence(Array.from(queries)).then(
21 (results) => {
22 resolve(\_(results).flatten());
23 }
24 );
25 }); // end of Promise
26 },
27 variables.throttle || 5
28 ); // end of syncedPoll
29 } else {
30 return track.artists;
31 }
32}When giving a full: 1 variable to album query, the resolver will instantiate a syncedPoll with a bulk-chunk querying system.
Better with a picture:
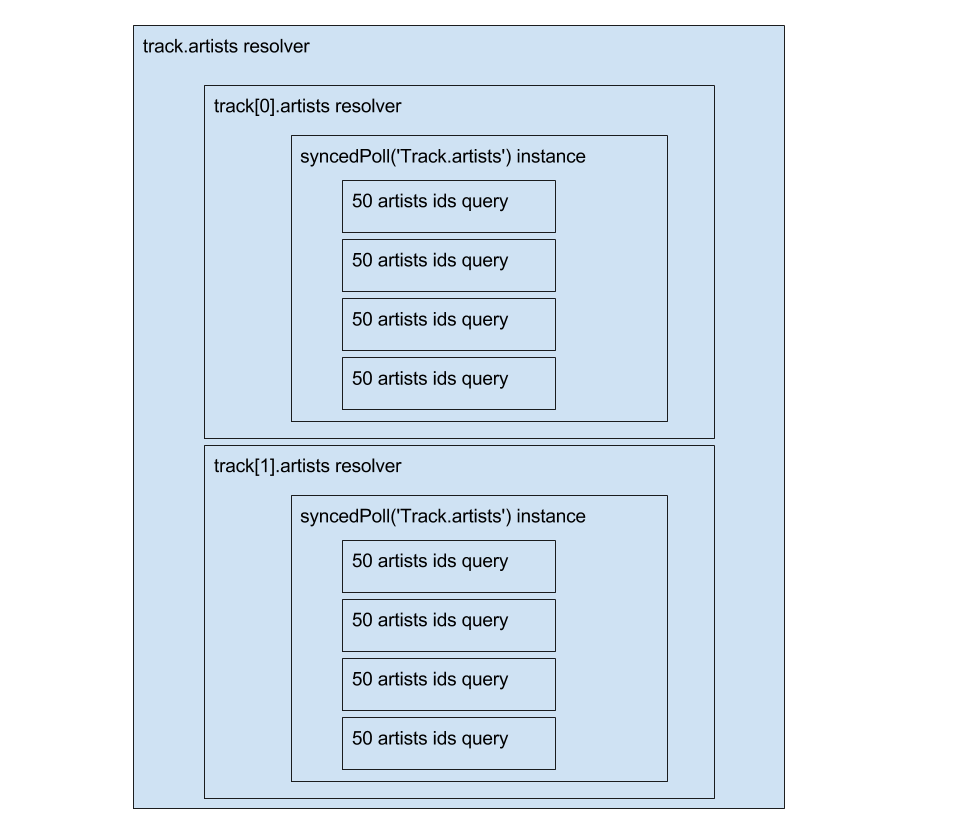
Each syncedPoll(‘Track.artists’) wait for a Promise queue to complete before releasing the “slot”.
All theses crazy queries are done without overlap, without API rate limiting issue 🙌
All theses crazy queries are done without overlap, without API rate limiting issue 🙌
We use cookies to collect statistics through Google Analytics.